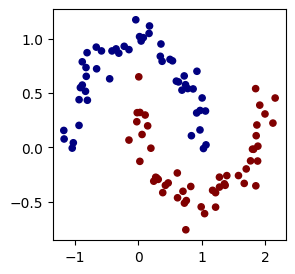
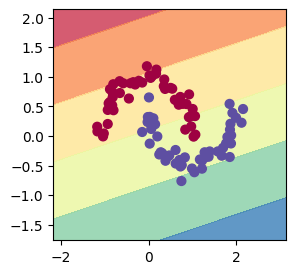
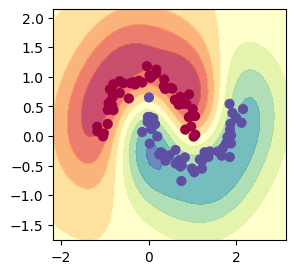
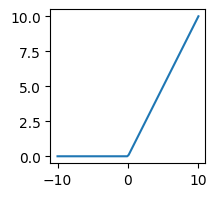
[Parameter containing:
tensor([[-0.5424, 0.7035],
[ 0.4790, -0.5349],
[-0.6747, -0.5768],
[ 0.5443, 0.4128],
[ 0.4504, -0.0185],
[-0.0441, -0.2940],
[ 0.2080, 0.0831],
[ 0.6219, -0.2243],
[-0.3513, -0.5343],
[ 0.1016, 0.0229],
[ 0.4938, -0.1573],
[-0.6393, 0.6179],
[-0.4360, 0.6501],
[-0.3244, -0.5963],
[ 0.1382, -0.2151],
[ 0.2515, 0.0522],
[-0.1192, -0.4686],
[-0.3790, -0.6068],
[ 0.6297, 0.0165],
[ 0.0684, -0.3553],
[-0.4688, -0.1745],
[ 0.6979, 0.3253],
[-0.2037, -0.0049],
[-0.4023, -0.6557],
[ 0.5090, 0.6831],
[-0.6267, 0.4039],
[ 0.0969, -0.3813],
[-0.1846, 0.5267],
[-0.5365, -0.1084],
[ 0.1364, 0.2271],
[-0.1810, -0.5180],
[ 0.6308, -0.5346],
[-0.2332, 0.5484],
[ 0.5378, -0.2781],
[-0.4441, 0.0723],
[ 0.4142, -0.3923],
[ 0.6986, -0.2161],
[-0.6811, -0.6203],
[-0.0687, -0.6008],
[-0.5971, -0.5685],
[-0.4439, 0.3425],
[-0.2736, -0.3446],
[ 0.3867, -0.3872],
[-0.0335, -0.4711],
[ 0.3715, -0.5554],
[-0.0277, -0.6428],
[ 0.5815, 0.2710],
[ 0.6715, 0.0902],
[-0.6584, 0.4558],
[-0.3908, 0.4174],
[-0.4921, 0.3944],
[-0.1185, -0.5256],
[-0.3669, -0.2472],
[ 0.3748, 0.2981],
[ 0.6042, 0.4914],
[-0.0695, 0.3853],
[-0.0547, -0.1053],
[ 0.2980, 0.0690],
[-0.0740, 0.5631],
[ 0.5119, 0.4708],
[-0.2598, -0.1661],
[ 0.0789, 0.4430],
[ 0.5331, -0.3026],
[-0.0920, 0.6451],
[ 0.3694, -0.4454],
[ 0.3215, -0.1403],
[-0.6530, 0.6804],
[-0.5663, -0.6449],
[ 0.3555, -0.2063],
[-0.5318, -0.4910],
[ 0.2442, -0.0347],
[-0.0851, 0.1557],
[ 0.6088, -0.3358],
[ 0.4101, -0.0757],
[-0.5733, 0.5278],
[ 0.3048, -0.2252],
[ 0.2347, -0.5549],
[ 0.6506, 0.3433],
[-0.2510, -0.1374],
[ 0.1557, -0.5080],
[ 0.3858, 0.1640],
[-0.3917, 0.1133],
[ 0.4641, -0.2426],
[-0.0062, -0.0962],
[-0.7030, -0.4290],
[ 0.2620, 0.6991],
[ 0.2901, -0.0909],
[ 0.0775, 0.3805],
[ 0.3271, 0.3051],
[ 0.3031, -0.1134],
[ 0.6571, 0.2422],
[-0.1762, -0.0181],
[ 0.2865, 0.4730],
[ 0.5359, -0.2990],
[ 0.1916, -0.0172],
[ 0.2190, 0.0258],
[-0.1729, -0.1995],
[ 0.6813, -0.2093],
[-0.3634, -0.5067],
[ 0.0432, -0.4079]], requires_grad=True),
Parameter containing:
tensor([ 0.5766, 0.6162, -0.2686, -0.1578, 0.6865, 0.2634, -0.6985, -0.3425,
0.2906, -0.0114, -0.6775, 0.5036, 0.6332, 0.6751, -0.5977, -0.0491,
-0.4500, 0.1250, 0.4903, -0.5717, -0.3245, 0.7017, 0.4344, -0.0473,
0.6803, -0.5600, 0.6484, -0.3195, -0.3139, 0.1952, -0.4479, -0.2100,
-0.6646, 0.4201, -0.5233, -0.7043, -0.6823, -0.2647, 0.6718, 0.0995,
0.2347, -0.3565, -0.6797, -0.2468, -0.5462, -0.2494, 0.6267, -0.4579,
0.1594, -0.1059, 0.1741, 0.3209, 0.3641, 0.5875, 0.6292, 0.0809,
-0.4876, 0.3994, 0.3152, 0.3648, 0.4063, 0.5700, -0.3156, 0.2266,
-0.2174, -0.6211, 0.5594, 0.5883, -0.0446, 0.4230, -0.4219, 0.5823,
-0.4527, 0.5416, 0.0796, -0.5627, -0.6555, 0.3130, -0.5378, -0.5302,
0.5915, 0.4088, -0.0572, -0.4736, -0.4032, 0.3197, 0.5996, 0.1356,
0.0157, 0.4295, -0.4658, 0.0418, 0.1956, -0.1381, 0.5843, -0.6962,
0.7021, 0.1144, 0.1079, -0.2890], requires_grad=True),
Parameter containing:
tensor([[ 0.0300, 0.0562, -0.0254, ..., 0.0396, 0.0815, 0.0362],
[ 0.0566, -0.0878, -0.0213, ..., 0.0637, -0.0571, -0.0919],
[ 0.0715, -0.0562, -0.0772, ..., 0.0187, 0.0198, -0.0824],
...,
[-0.0253, 0.0951, -0.0962, ..., 0.0042, 0.0782, 0.0413],
[ 0.0764, -0.0383, 0.0017, ..., 0.0361, -0.0970, 0.0323],
[ 0.0625, 0.0676, -0.0475, ..., -0.0465, -0.0302, 0.0808]],
requires_grad=True),
Parameter containing:
tensor([-0.0639, 0.0706, -0.0876, -0.0785, 0.0775, -0.0300, -0.0309, 0.0910,
-0.0494, -0.0925, 0.0996, 0.0852, 0.0539, -0.0580, -0.0104, -0.0786,
0.0823, -0.0027, -0.0224, -0.0260, -0.0658, 0.0488, 0.0040, 0.0013,
0.0806, 0.0613, -0.0825, 0.0785, 0.0981, 0.0256, -0.0052, 0.0891,
0.0055, -0.0467, 0.0638, -0.0601, 0.0716, -0.0211, 0.0557, 0.0992,
-0.0101, 0.0471, -0.0246, 0.0489, -0.0496, -0.0218, -0.0449, 0.0483,
-0.0109, -0.0282, -0.0430, 0.0874, 0.0675, 0.0911, -0.0311, 0.0348,
0.0353, 0.0062, -0.0925, -0.0489, 0.0525, -0.0471, -0.0320, -0.0381,
0.0685, 0.0760, 0.0911, -0.0442, 0.0980, -0.0511, -0.0691, -0.0337,
-0.0795, -0.0031, -0.0469, 0.0666, -0.0775, -0.0268, -0.0758, 0.0721,
0.0313, 0.0012, 0.0692, -0.0377, 0.0745, 0.0142, -0.0032, -0.0002,
-0.0487, 0.0178, -0.0806, -0.0408, -0.0385, 0.0324, 0.0940, 0.0446,
-0.0571, 0.0860, -0.0227, -0.0787], requires_grad=True),
Parameter containing:
tensor([[ 0.0054, 0.0240, 0.0851, -0.0097, -0.0265, -0.0703, 0.0274, -0.0753,
-0.0101, 0.0165, 0.0150, 0.0237, 0.0123, -0.0553, 0.0996, -0.0362,
0.0251, -0.0444, 0.0493, -0.0754, -0.0934, 0.0586, -0.0446, 0.0375,
0.0862, 0.0257, -0.0472, 0.0063, 0.0117, -0.0609, 0.0091, 0.0043,
0.0680, 0.0991, 0.0335, 0.0497, 0.0767, 0.0519, -0.0034, 0.0226,
-0.0051, -0.0873, -0.0179, -0.0677, -0.0845, -0.0004, -0.0272, 0.0025,
0.0660, 0.0548, -0.0171, -0.0898, -0.0385, 0.0122, 0.0312, -0.0176,
-0.0720, -0.0951, 0.0736, -0.0603, 0.0005, -0.0102, 0.0620, 0.0057,
-0.0069, -0.0003, -0.0871, -0.0360, 0.0035, 0.0284, 0.0026, -0.0300,
0.0589, 0.0258, -0.0543, -0.0633, 0.0105, 0.0539, -0.0429, 0.0446,
0.0227, 0.0534, 0.0607, -0.0648, 0.0136, 0.0441, 0.0281, 0.0790,
0.0393, 0.0064, 0.0039, -0.0891, 0.0406, 0.0153, 0.0834, 0.0591,
0.0224, 0.0256, 0.0980, 0.0237]], requires_grad=True),
Parameter containing:
tensor([0.0444], requires_grad=True)]