from torchvision.datasets import MNIST
import torchvision.transforms as transformsv1
import torch.nn as nn
from torch.optim import Adam
import torch
import torch.utils.data
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import matplotlib.pyplot as plt ![]()
Семинар 7: AE, VAE, Diffusion
План
- Recap
- AE
- VAE
- Diffusion
- Блиц
- Домашки
Recap: GAN
На прошлом занятии мы разобрали GAN:
- Генератор \(G\) получает случайный шум \(z\) и пытается сгенерировать реалистичный объект.
- Дискриминатор \(D\) получает объект и предсказывает, настоящий он или сгенерированный.
- Обучение идёт в формате adversarial training: генератор и дискриминатор соревнуются, и за счёт этого генератор постепенно улучшает качество выборок.
GAN — мощный подход, но не единственный. Помимо GAN есть и другие генеративные модели: AE, VAE, Diffusion. В этом семинаре фокусируемся на них и сравниваем их идеи с GAN-подходом.
AutoEncoder
Автоэнкодер — модель из двух частей: encoder переводит вход в компактное представление (латент), decoder по латенту восстанавливает вход. Задача обучения — минимизировать reconstruction loss (например, MSE или L1 между входом и выходом). Узкое место между encoder и decoder (bottleneck) заставляет модель выделять главные признаки.
Классические автоэнкодеры (Hinton & Salakhutdinov, 2006) использовались для предобучения и сжатия; сейчас их применяют для генерации (интерполяция в латенте), детекции аномалий и как часть более сложных моделей.
transforms = transformsv1.Compose([
transformsv1.ToTensor(),
])
mnist_dataset = MNIST("./MNIST", download=True, transform=transforms)
len(mnist_dataset)100%|██████████| 9.91M/9.91M [00:00<00:00, 20.9MB/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 500kB/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 4.65MB/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 15.0MB/s]60000class ImageEncoder(nn.Module):
"""Свёрточный encoder: изображение [B, 1, 28, 28] -> латент [B, latent_dim*14*14]."""
def __init__(self, latent_dim=128):
super().__init__()
self.latent_dim = latent_dim
self.sequential = nn.Sequential(*[
nn.BatchNorm2d(1),
nn.Conv2d(1, 64, kernel_size=3, padding=1), # [ bs, 64, 28, 28 ]
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, kernel_size=3, padding=1), # [ bs, 128, 28, 28 ]
nn.MaxPool2d(2), # [ bs, 128, 14, 14 ]
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, self.latent_dim, kernel_size=1), # [ bs, latent_dim, 14, 14 ]
nn.Flatten(1),
])
def forward(self, images_batch):
return self.sequential(images_batch)
class ImageDecoder(nn.Module):
"""Свёрточный decoder: латент [B, latent_dim*14*14] -> изображение [B, 1, 28, 28]."""
def __init__(self, latent_dim=128):
super().__init__()
self.latent_dim = latent_dim
self.sequential = nn.Sequential(*[
nn.Unflatten(1, (self.latent_dim, 14, 14)),
nn.BatchNorm2d(self.latent_dim),
nn.Conv2d(128, 64, kernel_size=1), # [ bs, 64, 14, 14 ]
nn.Upsample([28, 28]), # [ bs, 64, 28, 28 ]
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64, 1, kernel_size=3, padding=1), # [ bs, 1, 28, 28 ]
nn.ReLU(),
nn.BatchNorm2d(1),
nn.Conv2d(1, 1, kernel_size=3, padding=1), # [ bs, 1, 28, 28 ]
nn.Sigmoid(),
])
def forward(self, image_embedding):
# image_embedding ~ [ bs, 128 ]
# print("image_embedding", image_embedding.shape)
assert len(image_embedding.shape) == 2
assert image_embedding.shape[1] == self.latent_dim * 14 * 14, f"{image_embedding.shape[1]} == {self.latent_dim}"
# image_embedding = image_embedding.reshape(-1, self.latent_dim)
return self.sequential(image_embedding)
class AutoEncoder(nn.Module):
"""Автоэнкодер: encoder + decoder, forward возвращает восстановленное изображение."""
def __init__(self):
super().__init__()
self.encoder = ImageEncoder()
self.decoder = ImageDecoder()
def encode(self, images_batch):
return self.encoder(images_batch)
def decode(self, images_embeddings):
return self.decoder(images_embeddings)
def forward(self, images_batch):
images_embeddings = self.encode(images_batch)
# if self.training:
# images_embeddings += torch.randn_like(images_embeddings)
return self.decode(images_embeddings)
mnist_dataset[0][0].shapetorch.Size([1, 28, 28])AutoEncoder().forward( torch.rand( [ 5, 1, 28, 28 ] ) ).shapetorch.Size([5, 1, 28, 28])def train(
model: nn.Module,
dataset: torch.utils.data.Dataset,
loss_function: nn.Module,
num_epochs: int = 10,
device: str = "cuda",
learning_rate: float = 3e-4,
) -> None:
"""
Обучает модель (AE/VAE) на датасете с разделением на train/val.
Args:
model: Модель с forward(x) -> recon (и опционально mu, logvar для VAE).
dataset: Датасет изображений.
loss_function: Функция потерь (recon, x) или (recon, x, mu, logvar).
num_epochs: Количество эпох.
device: Устройство (cuda/cpu).
learning_rate: Learning rate для Adam.
"""
generator = torch.Generator().manual_seed(42)
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [0.9, 0.1], generator=generator)
model = model.to(device)
optimizer = Adam(model.parameters(), lr=learning_rate)
train_dataloader = DataLoader(train_dataset, batch_size=100, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=100, shuffle=False)
progress_bar = tqdm(range(num_epochs), total=num_epochs, desc="Epoch")
for epoch_num in progress_bar:
# train dataloader
train_losses_sum = torch.tensor([0.0], device=device)
train_iterations = 0
for images_batch in train_dataloader:
images_batch = images_batch[0].to(device)
restored_images_batch = model(images_batch)
loss = loss_function(restored_images_batch, images_batch)
train_losses_sum += loss.detach()
train_iterations += 1
optimizer.zero_grad()
loss.backward()
optimizer.step()
# validation
val_losses_sum = torch.tensor([0.0], device=device)
valid_iterations = 0
with torch.no_grad():
for images_batch in val_dataloader:
images_batch = images_batch[0].to(device)
valid_iterations += 1
restored_images_batch = model(images_batch)
loss = loss_function(restored_images_batch, images_batch)
val_losses_sum += loss.mean()
mean_val_loss = (val_losses_sum / valid_iterations).item()
mean_train_loss = (train_losses_sum / train_iterations).item()
progress_bar.set_postfix({"val_loss": f"{mean_val_loss:.2f}", "train_loss": f"{mean_train_loss:.2f}"})
# print(f"epoch {epoch_num} val_loss={mean_val_loss}")
autoencoder = AutoEncoder()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
generator = torch.Generator().manual_seed(42)
# cfair_dataset_5p, _ = torch.utils.data.random_split(cfair_dataset, [0.1, 0.9], generator=generator)
# print("cfair_dataset_5p", len(cfair_dataset_5p))
train(autoencoder, mnist_dataset, nn.L1Loss(), device=device, num_epochs=10, learning_rate=3e-4)@torch.no_grad()
def linear_latent_space_interpolation(
model: nn.Module,
image_from: torch.Tensor,
image_to: torch.Tensor,
device: str = "cpu",
num_interpolation_steps: int = 10,
) -> list:
"""
Строит линейную интерполяцию между двумя изображениями в латентном пространстве модели.
Args:
model: Модель с методами encode и decode.
image_from: Исходное изображение (без batch).
image_to: Конечное изображение.
device: Устройство.
num_interpolation_steps: Количество шагов интерполяции.
Returns:
Список массивов восстановленных изображений по шагам.
"""
model.eval()
image_from = image_from.unsqueeze(0).to(device)
image_to = image_to.unsqueeze(0).to(device)
model = model.to(device)
latent_space_from = model.encode(image_from)
latent_space_to = model.encode(image_to)
latent_space_steps = torch.linspace(0, 1, num_interpolation_steps)
latent_diff = latent_space_to - latent_space_from
restored_images = []
for latent_step_portion in latent_space_steps:
latent_step = latent_diff * latent_step_portion
latent_interpolation = latent_space_from + latent_step
restored_image = model.decode(latent_interpolation).detach().clip(0, 1).cpu().numpy()[0]
restored_images.append(restored_image)
return restored_imagesautoencoder.eval()
zero_autoencoder_prediction = autoencoder(mnist_dataset[7][0].unsqueeze(0).to(device))
plt.imshow(zero_autoencoder_prediction.permute(0, 2, 3, 1).detach().cpu().numpy()[0])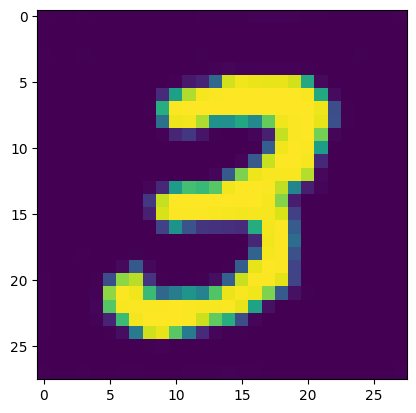
plt.imshow(mnist_dataset[7][0].permute(1,2, 0).numpy())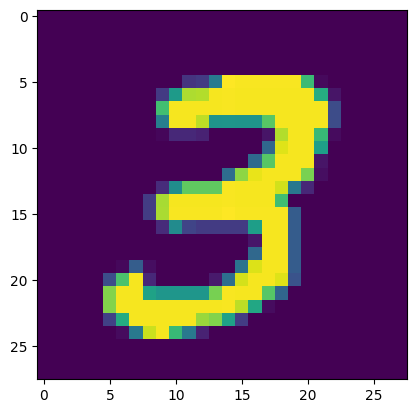
device = 'cuda' if torch.cuda.is_available() else 'cpu'
autoencoder_interpolated = linear_latent_space_interpolation(
autoencoder, mnist_dataset[1][0], mnist_dataset[2][0],
device=device,
num_interpolation_steps=10
)
_, axs = plt.subplots(2, 5, figsize=(10, 4))
axs = axs.flatten()
for img, ax in zip(autoencoder_interpolated, axs):
ax.imshow(img.T)
plt.show()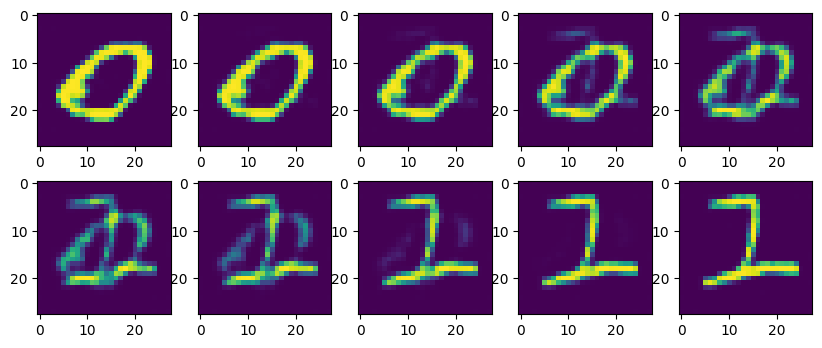
from html import escape
from IPython.display import HTML, display
from pathlib import Path
html_text = Path("static/ae_vs_vae_latent_space.html").read_text(encoding="utf-8")
display(HTML(html_text))Autoencoder latent space
Deterministic points. Gaps between clusters produce meaningless outputs when sampled.
VAE latent space
Overlapping distributions. Smooth, continuous — every point decodes to something plausible.
VAE (Variational AutoEncoder)
Мотивация: У обычного AE латентное пространство может быть «рваным»: близкие точки в латенте не обязательно дают похожие изображения. Генерация как сэмплирование из латента ненадёжна. VAE Kingma & Welling, 2013 моделирует латент как случайную величину с нормальным распределением \(q_\phi(z|x)\) (encoder выдаёт \(\mu\) и \(\log\sigma^2\)), а декодер восстанавливает \(x\) из \(z\).
Reparametrization trick: Сэмплирование \(z \sim \mathcal{N}(\mu, \sigma^2)\) недифференцируемо по \(\mu, \sigma\). Пишем \(z = \mu + \sigma \cdot \epsilon\), где \(\epsilon \sim \mathcal{N}(0, 1)\) — градиенты идут по \(\mu\) и \(\sigma\).

from html import escape
from IPython.display import HTML, display
from pathlib import Path
html_text = Path("static/elbo.html").read_text(encoding="utf-8")
html_text = html_text.replace("<body>", '<body style="background:#faf9f6;">', 1)
iframe = (
'<iframe style="width:100%;height:650px;border:0;background:#faf9f6;" '
'srcdoc="{srcdoc}"></iframe>'
).format(srcdoc=escape(html_text, quote=True))
display(HTML(iframe))def reparametrize(mu: torch.Tensor, logvar: torch.Tensor, generator: torch.Generator | None = None) -> torch.Tensor:
"""
Reparametrization trick: z = mu + sigma * epsilon, epsilon ~ N(0, 1).
Позволяет backprop через сэмпл z по параметрам mu и logvar.
Args:
mu: Средние [B, latent_dim].
logvar: Логарифм дисперсии [B, latent_dim].
generator: Генератор для воспроизводимости.
Returns:
Сэмпл z [B, latent_dim], дифференцируемый по mu и logvar.
"""
sigma = torch.exp(0.5 * logvar)
epsilon = torch.randn_like(mu, generator=generator)
return mu + sigma * epsilon
# Проверка: градиенты должны идти по mu и logvar
torch.manual_seed(42)
mu = torch.randn(2, 4, requires_grad=True)
logvar = torch.zeros(2, 4, requires_grad=True)
z = reparametrize(mu, logvar)
loss = z.sum()
loss.backward()
assert mu.grad is not None and logvar.grad is not None, "Градиенты по mu и logvar должны быть вычислены"
print("Reparametrization trick: градиенты по mu и logvar успешно вычислены.")
print("mu.grad norm:", mu.grad.norm().item())
print("logvar.grad norm:", logvar.grad.norm().item())Reparametrization trick: градиенты по mu и logvar успешно вычислены.
mu.grad norm: 2.8284270763397217
logvar.grad norm: 1.342544436454773❓ Вопрос: Что произойдет, если убрать KL-слагаемое из лосса VAE?
Ответ
Модель начнет работать почти как обычный автоэнкодер: реконструкция станет лучше на train,
но латентное пространство перестанет быть гладким и согласованным с \(\mathcal{N}(0, I)\).
Из-за этого генерация новых сэмплов из случайного \(z\) обычно заметно ухудшается.
❓ Вопрос: Как меняется поведение модели, если слишком сильно увеличить вес KL (beta в beta-VAE)?
Ответ
Сильный KL принуждает постериор быть слишком близким к prior,
поэтому латентный код несет мало информации о входе (posterior collapse).
Реконструкции становятся более размытыми/плохими, но латентное пространство может быть более регулярным.
❓ Вопрос: Чем отличается “хорошая реконструкция” от “хорошего латентного пространства”?
Ответ
Хорошая реконструкция означает, что декодер точно восстанавливает конкретные входы.
Хорошее латентное пространство означает, что в нем есть структура: близкие объекты рядом,
интерполяции осмысленны, а случайная выборка из prior дает правдоподобные примеры.
Идеально нужен баланс между этими двумя целями.
Diffusion

DDPM
DDPM (Denoising Diffusion Probabilistic Models) — это генеративные модели, которые учатся постепенно восстанавливать данные из шума. Идея состоит из двух процессов:
- Forward process: на каждом шаге к данным добавляется небольшой гауссов шум, и в итоге после многих шагов получаем почти чистый шум.
- Reverse process: модель учится по зашумлённому объекту \(x_t\) и номеру шага \(t\) предсказывать шум (или эквивалентно направление денойзинга), чтобы постепенно двигаться обратно к данным.
В этой реализации модель предсказывает именно шум \(\epsilon\), а NoiseScheduler задаёт коэффициенты и формулы для добавления/удаления шума.
Код основан на https://github.com/tanelp/tiny-diffusion/tree/master
! curl https://raw.githubusercontent.com/tanelp/tiny-diffusion/master/static/DatasaurusDozen.tsv -o static/DatasaurusDozen.tsv % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 64046 100 64046 0 0 65439 0 --:--:-- --:--:-- --:--:-- 65486import numpy as np
import pandas as pd
import torch
from torch.utils.data import TensorDataset
def dino_dataset(n=8000):
df = pd.read_csv("static/DatasaurusDozen.tsv", sep="\t")
df = df[df["dataset"] == "dino"]
rng = np.random.default_rng(42)
ix = rng.integers(0, len(df), n)
x = df["x"].iloc[ix].tolist()
x = np.array(x) + rng.normal(size=len(x)) * 0.15
y = df["y"].iloc[ix].tolist()
y = np.array(y) + rng.normal(size=len(x)) * 0.15
x = (x/54 - 1) * 4
y = (y/48 - 1) * 4
X = np.stack((x, y), axis=1)
return TensorDataset(torch.from_numpy(X.astype(np.float32)))
def get_dataset(name, n=8000):
if name == "dino":
return dino_dataset(n)
else:
raise ValueError(f"Unknown dataset: {name}")Компонент позиционных эмбеддингов
Шаг диффузии \(t\) и координаты входа кодируются через learnable positional embeddings. Это помогает MLP учитывать время (уровень шума) и работать с более выразительным представлением входа.
'''Learnable positional embeddings для DDPM.'''
import torch
from torch import nn
from torch.nn import functional as F
class LearnablePositionalEmbedding(nn.Module):
def __init__(self, size: int, scale: float = 1.0):
super().__init__()
self.size = size
self.scale = scale
self.layer = nn.Sequential(
nn.Linear(1, size),
nn.GELU(),
nn.Linear(size, size),
)
def forward(self, x: torch.Tensor):
x = x.float().unsqueeze(-1) * self.scale
return self.layer(x)
def __len__(self):
return self.size
class PositionalEmbedding(nn.Module):
def __init__(self, size: int, scale: float = 1.0):
super().__init__()
self.layer = LearnablePositionalEmbedding(size=size, scale=scale)
def forward(self, x: torch.Tensor):
return self.layer(x)Модель шума и NoiseScheduler
- Модель (
MLP) получает пару(x_t, t)и предсказывает шум \(\epsilon_\theta(x_t, t)\). NoiseSchedulerхранит расписаниеbeta/alphaи все предвычисленные коэффициенты для:- добавления шума в прямом процессе (
add_noise), - шага обратного процесса при генерации (
step), - вспомогательных вычислений
reconstruct_x0,q_posteriorи дисперсии.
- добавления шума в прямом процессе (
Именно связка «модель + scheduler» реализует практический DDPM-пайплайн.
# https://github.com/tanelp/tiny-diffusion/blob/master/ddpm.py
import argparse
import os
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import matplotlib.pyplot as plt
import numpy as np
class Block(nn.Module):
def __init__(self, size: int):
super().__init__()
self.ff = nn.Linear(size, size)
self.act = nn.GELU()
def forward(self, x: torch.Tensor):
return x + self.act(self.ff(x))
class MLP(nn.Module):
def __init__(self, hidden_size: int = 128, hidden_layers: int = 3, emb_size: int = 128):
super().__init__()
self.time_mlp = PositionalEmbedding(emb_size)
self.input_mlp1 = PositionalEmbedding(emb_size, scale=25.0)
self.input_mlp2 = PositionalEmbedding(emb_size, scale=25.0)
concat_size = len(self.time_mlp.layer) + \
len(self.input_mlp1.layer) + len(self.input_mlp2.layer)
layers = [nn.Linear(concat_size, hidden_size), nn.GELU()]
for _ in range(hidden_layers):
layers.append(Block(hidden_size))
layers.append(nn.Linear(hidden_size, 2))
self.joint_mlp = nn.Sequential(*layers)
def forward(self, x, t):
# x имеет форму [batch_size, 2]
# В этой реализации ожидается фиксированная размерность входа
x1_emb = self.input_mlp1(x[:, 0])
x2_emb = self.input_mlp2(x[:, 1])
t_emb = self.time_mlp(t)
x = torch.cat((x1_emb, x2_emb, t_emb), dim=-1)
x = self.joint_mlp(x)
return x
class NoiseScheduler():
def __init__(self,
num_timesteps=1000,
beta_start=0.0001,
beta_end=0.02,
beta_schedule="linear"):
self.num_timesteps = num_timesteps
if beta_schedule == "linear":
self.betas = torch.linspace(
beta_start, beta_end, num_timesteps, dtype=torch.float32)
elif beta_schedule == "quadratic":
self.betas = torch.linspace(
beta_start ** 0.5, beta_end ** 0.5, num_timesteps, dtype=torch.float32) ** 2
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, axis=0)
self.alphas_cumprod_prev = F.pad(
self.alphas_cumprod[:-1], (1, 0), value=1.)
# Предрасчёты для добавления шума в прямом процессе
self.sqrt_alphas_cumprod = self.alphas_cumprod ** 0.5
self.sqrt_one_minus_alphas_cumprod = (1 - self.alphas_cumprod) ** 0.5
# Предрасчёты для восстановления оценки x0
self.sqrt_inv_alphas_cumprod = torch.sqrt(1 / self.alphas_cumprod)
self.sqrt_inv_alphas_cumprod_minus_one = torch.sqrt(
1 / self.alphas_cumprod - 1)
# Предрасчёты для параметров q-постериора
self.posterior_mean_coef1 = self.betas * torch.sqrt(self.alphas_cumprod_prev) / (1. - self.alphas_cumprod)
self.posterior_mean_coef2 = (1. - self.alphas_cumprod_prev) * torch.sqrt(self.alphas) / (1. - self.alphas_cumprod)
def reconstruct_x0(self, x_t, t, noise):
s1 = self.sqrt_inv_alphas_cumprod[t]
s2 = self.sqrt_inv_alphas_cumprod_minus_one[t]
s1 = s1.reshape(-1, 1)
s2 = s2.reshape(-1, 1)
return s1 * x_t - s2 * noise
def q_posterior(self, x_0, x_t, t):
s1 = self.posterior_mean_coef1[t]
s2 = self.posterior_mean_coef2[t]
s1 = s1.reshape(-1, 1)
s2 = s2.reshape(-1, 1)
mu = s1 * x_0 + s2 * x_t
return mu
def get_variance(self, t):
if t == 0:
return 0
variance = self.betas[t] * (1. - self.alphas_cumprod_prev[t]) / (1. - self.alphas_cumprod[t])
variance = variance.clip(1e-20)
return variance
# Реализует один шаг обратного процесса
# https://arxiv.org/pdf/2208.11970
# Сэмплирование
def step(self, model_output, timestep, sample):
t = timestep
pred_original_sample = self.reconstruct_x0(sample, t, model_output)
# TODO: проверить, нужно ли здесь использовать t-1
pred_prev_sample = self.q_posterior(pred_original_sample, sample, t)
variance = 0
if t > 0:
noise = torch.randn_like(model_output)
variance = (self.get_variance(t) ** 0.5) * noise
pred_prev_sample = pred_prev_sample + variance
return pred_prev_sample
# Обучение: добавление шума по выбранным таймстепам
def add_noise(self, x_start, x_noise, timesteps):
s1 = self.sqrt_alphas_cumprod[timesteps]
s2 = self.sqrt_one_minus_alphas_cumprod[timesteps]
s1 = s1.reshape(-1, 1)
s2 = s2.reshape(-1, 1)
return s1 * x_start + s2 * x_noise
def __len__(self):
return self.num_timestepsfrom dataclasses import dataclass
@dataclass
class TrainingConfig():
experiment_name ="base"
dataset ="dino" # варианты=["circle", "dino", "line", "moons"]
train_batch_size = 32
eval_batch_size = 1000
num_epochs = 200
learning_rate = 1e-3
num_timesteps = 1000
beta_schedule = "linear" # варианты=["linear", "quadratic"]
embedding_size = 128
hidden_size = 128
hidden_layers = 3
save_images_step = 5
config = TrainingConfig()
dataset = get_dataset(config.dataset)
dataloader = DataLoader(
dataset, batch_size=config.train_batch_size, shuffle=True, drop_last=True)
model = MLP(
hidden_size=config.hidden_size,
hidden_layers=config.hidden_layers,
emb_size=config.embedding_size)
noise_scheduler = NoiseScheduler(
num_timesteps=config.num_timesteps,
beta_schedule=config.beta_schedule)
optimizer = torch.optim.AdamW(
model.parameters(),
lr=config.learning_rate,
)❓ Вопрос: На каких слоях и как используются timestep’ы в диффузионных моделях?
Ответ
Есть разные подходы: можно конкатенировать обучаемый эмбэддинг с вектором признаков и передать в MLP; можно закодировать через AdaLayerNorm — по сути добавляет смещение для сгенерированного сэмпла (пример в diffusers).
❓ Вопрос: Что является результатом вычисления .forward() для диффузионки?
Ответ
Обычно предсказывается шум, который надо вычесть из сэмпла.
Но есть разные стратегии: можно предсказывать шум; можно предсказывать предыдущий сэмпл \(x_{t-1}\); можно предсказывать исходный сэмпл \(x_0\).
Сравнение параметризаций в диффузионных моделях
Из \(\mathbf{x}_t = \sqrt{\bar\alpha_t}\,\mathbf{x}_0 + \sqrt{1-\bar\alpha_t}\,\boldsymbol{\epsilon}\) любые два из трёх \((\mathbf{x}_t, \mathbf{x}_0, \boldsymbol{\epsilon})\) однозначно определяют третий. Поэтому все параметризации алгебраически эквивалентны — разница только в неявном взвешивании loss по \(t\).
| \(\boldsymbol{\epsilon}\)-prediction | \(\mathbf{x}_0\)-prediction | \(\mathbf{v}\)-prediction | |
|---|---|---|---|
| Таргет | \(\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\) | \(\mathbf{x}_0\) (чистые данные) | \(\mathbf{v}_t = \sqrt{\bar\alpha_t}\,\boldsymbol{\epsilon} - \sqrt{1-\bar\alpha_t}\,\mathbf{x}_0\) |
| Вес на \(\|\mathbf{x}_0 - \hat{\mathbf{x}}_0\|^2\) | \(\text{SNR}_t\) (фокус на деталях) | \(1\) (равномерный) | \(1 + \text{SNR}_t\) (сбалансированный) |
| Стабильность | ✅ Дисперсия таргета = 1 для всех \(t\) | ⚠️ Большие градиенты при \(t \to T\) | ✅ Дисперсия таргета = 1 для всех \(t\) |
| Где используется | DDPM, Imagen, Guided Diffusion | Latent Diffusion, SD 1.x, DALL·E 2 | Progressive Distillation, SD 2.1+ |
❓ Вопрос: Почему для диффузии важно, чтобы \(x_t \sim q_t(x_t | x_0)\) (ф-ия .add_noise) можно было вычислять эффективно?
Ответ
Потому что во время обучения этот метод вызывается большое количество раз.
В теории можно заранее насэмплировать большой датасет с зашумлением на разных шагах, но это потребует большого количества диска.
TrainingConfig и инициализация
TrainingConfig хранит гиперпараметры эксперимента: размер батча, количество эпох, число диффузионных шагов, тип расписания beta, размер эмбеддингов и архитектуру MLP. Ниже мы создаём датасет/дataloader, модель, NoiseScheduler и оптимизатор.
Формулы для вычисления \(x_t\) в диффузии
Рекуррентная формула
\[ x_t = \sqrt{\alpha_t}\,x_{t-1} + \sqrt{1 - \alpha_t}\,\epsilon \]
Нерекуррентная формула
\[ x_t = \sqrt{\overline{\alpha}_t}\,x_0 + \sqrt{1 - \overline{\alpha}_t}\,\epsilon \]
Как связаны \(\alpha_t\) и \(\beta_t\)
\[ \alpha_t = 1 - \beta_t \]
\[ \overline{\alpha}_t = \prod_{s=1}^{t} \alpha_s = \prod_{s=1}^{t}(1-\beta_s) \]
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(10, 3), sharex=True)
# Начальные и конечные значения для alpha и beta
alpha_start = noise_scheduler.alphas[0].item()
alpha_end = noise_scheduler.alphas[-1].item()
beta_start = noise_scheduler.betas[0].item()
beta_end = noise_scheduler.betas[-1].item()
# Рекуррентная формула: коэффициенты при x_{t-1} и epsilon
axes[0].plot(torch.sqrt(noise_scheduler.alphas), label=r"$\sqrt{\alpha_t}$")
axes[0].plot(torch.sqrt(1 - noise_scheduler.alphas), label=r"$\sqrt{1-\alpha_t}$")
axes[0].set_title(r"Рекуррентно: $x_t=\sqrt{\alpha_t}x_{t-1}+\sqrt{1-\alpha_t}\epsilon$", fontsize=16)
axes[0].set_xlabel("t")
axes[0].set_ylabel("coefficient")
axes[0].grid(alpha=0.3)
axes[0].legend()
# Нерекуррентная формула: коэффициенты при x_0 и epsilon
axes[1].plot(noise_scheduler.sqrt_alphas_cumprod, label=r"$\sqrt{\overline{\alpha}_t}$")
axes[1].plot(noise_scheduler.sqrt_one_minus_alphas_cumprod, label=r"$\sqrt{1-\overline{\alpha}_t}$")
axes[1].set_title(r"Нерекуррентно: $x_t=\sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}\epsilon$", fontsize=16)
axes[1].set_xlabel("t")
axes[1].grid(alpha=0.3)
axes[1].legend()
fig.suptitle(r"Связь параметров: $\alpha_t=1-\beta_t$, $\overline{\alpha}_t=\prod_{s=1}^{t}(1-\beta_s)$", y=1.05, fontsize=16)
fig.text(
0.5,
-0.2,
f"alpha: start={alpha_start:.4f}, end={alpha_end:.2f} \n beta: start={beta_start:.4f}, end={beta_end:.2f}",
ha="center",
fontsize=16,
)
fig.tight_layout()
plt.show()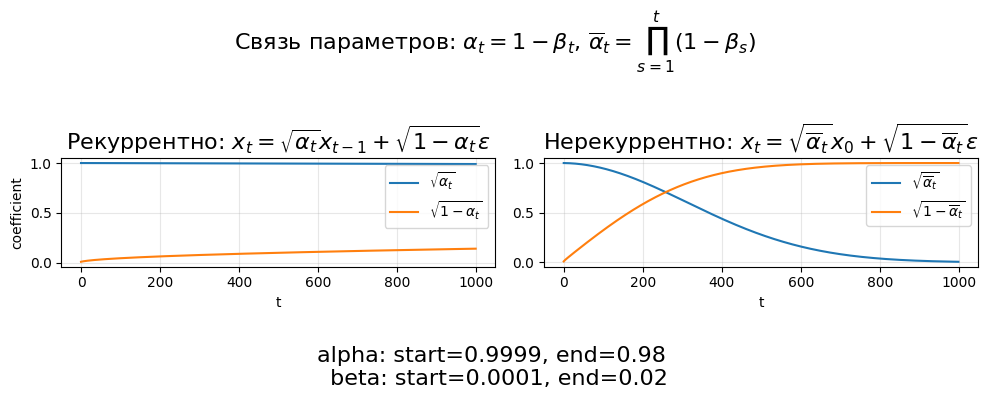
❓ Вопрос: Что интуитивно означает расписание beta_t и почему его форма важна?
Ответ
\(\beta_t\) задает, сколько нового шума добавляется на шаге \(t\).
Форма расписания определяет, как быстро теряется информация о данных по времени:
слишком резкое зашумление делает задачу денойзинга тяжелой, слишком мягкое - неэффективной по числу шагов.
Поэтому от расписания напрямую зависят стабильность обучения и качество/скорость сэмплирования.
import ipywidgets as widgets
from IPython.display import display
# Берем все точки динозавра и фиксируем шум для воспроизводимости.
x0 = dataset.tensors[0].cpu()
noise_generator = torch.Generator().manual_seed(42)
fixed_noise = torch.randn(x0.shape, generator=noise_generator)
def plot_forward_diffusion(t: int) -> None:
timesteps = torch.full((x0.shape[0],), t, dtype=torch.long)
x_t = noise_scheduler.add_noise(x0, fixed_noise, timesteps)
alpha_bar_t = noise_scheduler.alphas_cumprod[t].item()
plt.figure(figsize=(4, 4))
plt.scatter(x0[:, 0], x0[:, 1], s=6, alpha=0.5, c="gray", label="$x_0$")
plt.scatter(x_t[:, 0], x_t[:, 1], s=7, alpha=0.25, c="tab:blue", label="$x_t$")
plt.title(f"Forward diffusion on dino dataset (t={t}, alpha_bar={alpha_bar_t:.4f})")
plt.xlim(-4.5, 4.5)
plt.ylim(-4.5, 4.5)
plt.gca().set_aspect("equal", adjustable="box")
plt.grid(alpha=0.2)
plt.legend(loc="upper right")
plt.show()
t_slider = widgets.IntSlider(
value=0,
min=0,
max=len(noise_scheduler) - 1,
step=1,
description="timestep",
continuous_update=False,
)
display(widgets.interactive_output(plot_forward_diffusion, {"t": t_slider}), t_slider)❓ Вопрос: Почему размытие не остается около исходных точек, а сходится к гауссиане?
Ответ
Из-за коэффициента \(\sqrt{\bar\alpha_t}\) перед сигналом.
Обучение и сэмплирование
В training loop на каждом шаге мы:
- Берём батч точек \(x_0\).
- Выбираем случайный шаг \(t\).
- Строим зашумлённый объект \(x_t\) через
noise_scheduler.add_noise(...). - Просим модель предсказать добавленный шум.
- Обучаемся по MSE между истинным шумом и предсказанным.
После каждой save_images_step эпохи запускаем sampling: стартуем с гауссова шума и идём по шагам времени в обратном порядке через noise_scheduler.step(...), постепенно получая точки, похожие на данные.
global_step = 0
frames = []
losses = []
print("Обучаем модель...")
for epoch in range(config.num_epochs):
model.train()
progress_bar = tqdm(total=len(dataloader))
progress_bar.set_description(f"Эпоха {epoch}")
for step, batch in enumerate(dataloader):
batch = batch[0] # [batch_size, 2]
noise = torch.rand_like(batch) # [batch_size, 2]
timesteps = torch.randint(
0, noise_scheduler.num_timesteps, (batch.shape[0],)
).long()
noisy = noise_scheduler.add_noise(batch, noise, timesteps)
noise_pred = model(noisy, timesteps)
loss = F.mse_loss(noise_pred, noise)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
optimizer.zero_grad()
progress_bar.update(1)
logs = {"loss": loss.detach().item(), "step": global_step}
losses.append(loss.detach().item())
progress_bar.set_postfix(**logs)
global_step += 1
progress_bar.close()
if epoch % config.save_images_step == 0 or epoch == config.num_epochs - 1:
# Генерируем точки, чтобы потом визуализировать прогресс обучения
model.eval()
sample = torch.randn(config.eval_batch_size, 2)
timesteps = list(range(len(noise_scheduler)))[::-1]
for i, t in enumerate(tqdm(timesteps)):
t = torch.from_numpy(np.repeat(t, config.eval_batch_size)).long()
with torch.no_grad():
residual = model(sample, t)
sample = noise_scheduler.step(residual, t[0], sample)
frames.append(sample.numpy())
print("Сохраняем модель...")
outdir = f"exps/{config.experiment_name}"
os.makedirs(outdir, exist_ok=True)
torch.save(model.state_dict(), f"{outdir}/model.pth")
print("Сохраняем изображения...")
imgdir = f"{outdir}/images"
os.makedirs(imgdir, exist_ok=True)
frames = np.stack(frames)
xmin, xmax = -6, 6
ymin, ymax = -6, 6
for i, frame in enumerate(frames):
plt.figure(figsize=(10, 10))
plt.scatter(frame[:, 0], frame[:, 1])
plt.xlim(xmin, xmax)
plt.ylim(ymin, ymax)
plt.savefig(f"{imgdir}/{i:04}.png")
plt.close()
print("Сохраняем loss в numpy-массив...")
np.save(f"{outdir}/loss.npy", np.array(losses))
print("Сохраняем фреймы...")
np.save(f"{outdir}/frames.npy", frames)Обучаем модель...
Эпоха 0: 100%|██████████| 250/250 [00:00<00:00, 358.12it/s, loss=0.0795, step=249]
100%|██████████| 1000/1000 [00:02<00:00, 457.24it/s]
Эпоха 1: 100%|██████████| 250/250 [00:00<00:00, 321.87it/s, loss=0.0877, step=499]
Эпоха 2: 100%|██████████| 250/250 [00:00<00:00, 373.92it/s, loss=0.103, step=749]
Эпоха 3: 100%|██████████| 250/250 [00:00<00:00, 398.52it/s, loss=0.0867, step=999]
Эпоха 4: 100%|██████████| 250/250 [00:00<00:00, 365.72it/s, loss=0.0959, step=1249]
Эпоха 5: 100%|██████████| 250/250 [00:00<00:00, 399.26it/s, loss=0.0877, step=1499]
100%|██████████| 1000/1000 [00:01<00:00, 523.49it/s]
Эпоха 6: 100%|██████████| 250/250 [00:00<00:00, 401.58it/s, loss=0.0921, step=1749]
Эпоха 7: 100%|██████████| 250/250 [00:00<00:00, 355.57it/s, loss=0.0835, step=1999]
Эпоха 8: 100%|██████████| 250/250 [00:00<00:00, 356.34it/s, loss=0.0773, step=2249]
Эпоха 9: 100%|██████████| 250/250 [00:00<00:00, 389.19it/s, loss=0.0908, step=2499]
Эпоха 10: 100%|██████████| 250/250 [00:00<00:00, 355.27it/s, loss=0.0926, step=2749]
100%|██████████| 1000/1000 [00:01<00:00, 516.85it/s]
Эпоха 11: 100%|██████████| 250/250 [00:00<00:00, 377.87it/s, loss=0.0786, step=2999]
Эпоха 12: 100%|██████████| 250/250 [00:00<00:00, 329.23it/s, loss=0.0947, step=3249]
Эпоха 13: 100%|██████████| 250/250 [00:00<00:00, 364.53it/s, loss=0.0945, step=3499]
Эпоха 14: 100%|██████████| 250/250 [00:00<00:00, 369.51it/s, loss=0.0695, step=3749]
Эпоха 15: 100%|██████████| 250/250 [00:00<00:00, 334.12it/s, loss=0.0874, step=3999]
100%|██████████| 1000/1000 [00:02<00:00, 483.83it/s]
Эпоха 16: 100%|██████████| 250/250 [00:00<00:00, 408.40it/s, loss=0.0929, step=4249]
Эпоха 17: 100%|██████████| 250/250 [00:00<00:00, 361.15it/s, loss=0.098, step=4499]
Эпоха 18: 100%|██████████| 250/250 [00:00<00:00, 401.38it/s, loss=0.0777, step=4749]
Эпоха 19: 100%|██████████| 250/250 [00:00<00:00, 352.83it/s, loss=0.0793, step=4999]
Эпоха 20: 100%|██████████| 250/250 [00:00<00:00, 348.43it/s, loss=0.0912, step=5249]
100%|██████████| 1000/1000 [00:02<00:00, 474.43it/s]
Эпоха 21: 100%|██████████| 250/250 [00:00<00:00, 332.34it/s, loss=0.074, step=5499]
Эпоха 22: 100%|██████████| 250/250 [00:00<00:00, 377.00it/s, loss=0.0811, step=5749]
Эпоха 23: 100%|██████████| 250/250 [00:00<00:00, 351.08it/s, loss=0.0789, step=5999]
Эпоха 24: 100%|██████████| 250/250 [00:00<00:00, 387.76it/s, loss=0.0854, step=6249]
Эпоха 25: 100%|██████████| 250/250 [00:00<00:00, 380.16it/s, loss=0.0916, step=6499]
100%|██████████| 1000/1000 [00:02<00:00, 468.98it/s]
Эпоха 26: 100%|██████████| 250/250 [00:00<00:00, 355.58it/s, loss=0.0739, step=6749]
Эпоха 27: 100%|██████████| 250/250 [00:00<00:00, 369.63it/s, loss=0.0887, step=6999]
Эпоха 28: 100%|██████████| 250/250 [00:00<00:00, 435.19it/s, loss=0.0945, step=7249]
Эпоха 29: 100%|██████████| 250/250 [00:00<00:00, 456.82it/s, loss=0.0887, step=7499]
Эпоха 30: 100%|██████████| 250/250 [00:00<00:00, 371.64it/s, loss=0.0816, step=7749]
100%|██████████| 1000/1000 [00:02<00:00, 455.71it/s]
Эпоха 31: 100%|██████████| 250/250 [00:00<00:00, 373.20it/s, loss=0.0709, step=7999]
Эпоха 32: 100%|██████████| 250/250 [00:00<00:00, 434.71it/s, loss=0.086, step=8249]
Эпоха 33: 100%|██████████| 250/250 [00:00<00:00, 463.00it/s, loss=0.0809, step=8499]
Эпоха 34: 100%|██████████| 250/250 [00:00<00:00, 401.01it/s, loss=0.0768, step=8749]
Эпоха 35: 100%|██████████| 250/250 [00:00<00:00, 446.33it/s, loss=0.0968, step=8999]
100%|██████████| 1000/1000 [00:02<00:00, 431.22it/s]
Эпоха 36: 100%|██████████| 250/250 [00:00<00:00, 432.52it/s, loss=0.0909, step=9249]
Эпоха 37: 100%|██████████| 250/250 [00:00<00:00, 424.20it/s, loss=0.101, step=9499]
Эпоха 38: 100%|██████████| 250/250 [00:00<00:00, 306.06it/s, loss=0.0761, step=9749]
Эпоха 39: 100%|██████████| 250/250 [00:00<00:00, 409.25it/s, loss=0.0884, step=9999]
Эпоха 40: 100%|██████████| 250/250 [00:00<00:00, 448.60it/s, loss=0.094, step=10249]
100%|██████████| 1000/1000 [00:02<00:00, 459.98it/s]
Эпоха 41: 100%|██████████| 250/250 [00:00<00:00, 453.31it/s, loss=0.0807, step=10499]
Эпоха 42: 100%|██████████| 250/250 [00:00<00:00, 440.43it/s, loss=0.0891, step=10749]
Эпоха 43: 100%|██████████| 250/250 [00:00<00:00, 421.19it/s, loss=0.0982, step=10999]
Эпоха 44: 100%|██████████| 250/250 [00:00<00:00, 419.10it/s, loss=0.0865, step=11249]
Эпоха 45: 100%|██████████| 250/250 [00:00<00:00, 459.62it/s, loss=0.0863, step=11499]
100%|██████████| 1000/1000 [00:01<00:00, 533.18it/s]
Эпоха 46: 100%|██████████| 250/250 [00:00<00:00, 427.49it/s, loss=0.0985, step=11749]
Эпоха 47: 100%|██████████| 250/250 [00:00<00:00, 428.49it/s, loss=0.0853, step=11999]
Эпоха 48: 100%|██████████| 250/250 [00:00<00:00, 430.93it/s, loss=0.0739, step=12249]
Эпоха 49: 100%|██████████| 250/250 [00:00<00:00, 411.80it/s, loss=0.0929, step=12499]
Эпоха 50: 100%|██████████| 250/250 [00:00<00:00, 443.52it/s, loss=0.0805, step=12749]
100%|██████████| 1000/1000 [00:01<00:00, 516.29it/s]
Эпоха 51: 100%|██████████| 250/250 [00:00<00:00, 452.97it/s, loss=0.0862, step=12999]
Эпоха 52: 100%|██████████| 250/250 [00:00<00:00, 459.90it/s, loss=0.0882, step=13249]
Эпоха 53: 100%|██████████| 250/250 [00:00<00:00, 358.78it/s, loss=0.0704, step=13499]
Эпоха 54: 100%|██████████| 250/250 [00:00<00:00, 437.46it/s, loss=0.0853, step=13749]
Эпоха 55: 100%|██████████| 250/250 [00:00<00:00, 382.36it/s, loss=0.107, step=13999]
100%|██████████| 1000/1000 [00:01<00:00, 531.29it/s]
Эпоха 56: 100%|██████████| 250/250 [00:00<00:00, 448.01it/s, loss=0.0714, step=14249]
Эпоха 57: 100%|██████████| 250/250 [00:00<00:00, 451.78it/s, loss=0.0958, step=14499]
Эпоха 58: 100%|██████████| 250/250 [00:00<00:00, 447.30it/s, loss=0.0737, step=14749]
Эпоха 59: 100%|██████████| 250/250 [00:00<00:00, 392.24it/s, loss=0.0824, step=14999]
Эпоха 60: 100%|██████████| 250/250 [00:00<00:00, 468.22it/s, loss=0.0761, step=15249]
100%|██████████| 1000/1000 [00:01<00:00, 505.02it/s]
Эпоха 61: 100%|██████████| 250/250 [00:00<00:00, 412.72it/s, loss=0.0877, step=15499]
Эпоха 62: 100%|██████████| 250/250 [00:00<00:00, 457.38it/s, loss=0.0935, step=15749]
Эпоха 63: 100%|██████████| 250/250 [00:00<00:00, 398.90it/s, loss=0.0859, step=15999]
Эпоха 64: 100%|██████████| 250/250 [00:00<00:00, 460.79it/s, loss=0.0838, step=16249]
Эпоха 65: 100%|██████████| 250/250 [00:00<00:00, 451.46it/s, loss=0.0761, step=16499]
100%|██████████| 1000/1000 [00:01<00:00, 500.46it/s]
Эпоха 66: 100%|██████████| 250/250 [00:00<00:00, 458.18it/s, loss=0.0838, step=16749]
Эпоха 67: 100%|██████████| 250/250 [00:00<00:00, 456.66it/s, loss=0.0876, step=16999]
Эпоха 68: 100%|██████████| 250/250 [00:00<00:00, 454.62it/s, loss=0.0756, step=17249]
Эпоха 69: 100%|██████████| 250/250 [00:00<00:00, 463.89it/s, loss=0.0833, step=17499]
Эпоха 70: 100%|██████████| 250/250 [00:00<00:00, 427.96it/s, loss=0.0811, step=17749]
100%|██████████| 1000/1000 [00:01<00:00, 526.51it/s]
Эпоха 71: 100%|██████████| 250/250 [00:00<00:00, 460.27it/s, loss=0.0789, step=17999]
Эпоха 72: 100%|██████████| 250/250 [00:00<00:00, 427.67it/s, loss=0.0833, step=18249]
Эпоха 73: 100%|██████████| 250/250 [00:00<00:00, 437.22it/s, loss=0.097, step=18499]
Эпоха 74: 100%|██████████| 250/250 [00:00<00:00, 464.83it/s, loss=0.0793, step=18749]
Эпоха 75: 100%|██████████| 250/250 [00:00<00:00, 413.28it/s, loss=0.0953, step=18999]
100%|██████████| 1000/1000 [00:01<00:00, 510.44it/s]
Эпоха 76: 100%|██████████| 250/250 [00:00<00:00, 459.83it/s, loss=0.0789, step=19249]
Эпоха 77: 100%|██████████| 250/250 [00:00<00:00, 415.40it/s, loss=0.0799, step=19499]
Эпоха 78: 100%|██████████| 250/250 [00:00<00:00, 472.07it/s, loss=0.0759, step=19749]
Эпоха 79: 100%|██████████| 250/250 [00:00<00:00, 403.37it/s, loss=0.0918, step=2e+4]
Эпоха 80: 100%|██████████| 250/250 [00:00<00:00, 443.77it/s, loss=0.0707, step=20249]
100%|██████████| 1000/1000 [00:01<00:00, 529.09it/s]
Эпоха 81: 100%|██████████| 250/250 [00:00<00:00, 407.49it/s, loss=0.0813, step=20499]
Эпоха 82: 100%|██████████| 250/250 [00:00<00:00, 467.36it/s, loss=0.0779, step=20749]
Эпоха 83: 100%|██████████| 250/250 [00:00<00:00, 412.85it/s, loss=0.0765, step=20999]
Эпоха 84: 100%|██████████| 250/250 [00:00<00:00, 450.88it/s, loss=0.0811, step=21249]
Эпоха 85: 100%|██████████| 250/250 [00:00<00:00, 420.45it/s, loss=0.0859, step=21499]
100%|██████████| 1000/1000 [00:01<00:00, 501.05it/s]
Эпоха 86: 100%|██████████| 250/250 [00:00<00:00, 462.47it/s, loss=0.069, step=21749]
Эпоха 87: 100%|██████████| 250/250 [00:00<00:00, 424.44it/s, loss=0.0852, step=21999]
Эпоха 88: 100%|██████████| 250/250 [00:00<00:00, 443.66it/s, loss=0.0849, step=22249]
Эпоха 89: 100%|██████████| 250/250 [00:00<00:00, 409.39it/s, loss=0.101, step=22499]
Эпоха 90: 100%|██████████| 250/250 [00:00<00:00, 435.44it/s, loss=0.0985, step=22749]
100%|██████████| 1000/1000 [00:01<00:00, 515.48it/s]
Эпоха 91: 100%|██████████| 250/250 [00:00<00:00, 456.60it/s, loss=0.0816, step=22999]
Эпоха 92: 100%|██████████| 250/250 [00:00<00:00, 436.47it/s, loss=0.0575, step=23249]
Эпоха 93: 100%|██████████| 250/250 [00:00<00:00, 457.31it/s, loss=0.0737, step=23499]
Эпоха 94: 100%|██████████| 250/250 [00:00<00:00, 448.53it/s, loss=0.0749, step=23749]
Эпоха 95: 100%|██████████| 250/250 [00:00<00:00, 457.19it/s, loss=0.0748, step=23999]
100%|██████████| 1000/1000 [00:01<00:00, 543.78it/s]
Эпоха 96: 100%|██████████| 250/250 [00:00<00:00, 452.37it/s, loss=0.0903, step=24249]
Эпоха 97: 100%|██████████| 250/250 [00:00<00:00, 433.55it/s, loss=0.0781, step=24499]
Эпоха 98: 100%|██████████| 250/250 [00:00<00:00, 425.78it/s, loss=0.0985, step=24749]
Эпоха 99: 100%|██████████| 250/250 [00:00<00:00, 458.92it/s, loss=0.0807, step=24999]
Эпоха 100: 100%|██████████| 250/250 [00:00<00:00, 399.92it/s, loss=0.0811, step=25249]
100%|██████████| 1000/1000 [00:01<00:00, 500.55it/s]
Эпоха 101: 100%|██████████| 250/250 [00:00<00:00, 411.21it/s, loss=0.0737, step=25499]
Эпоха 102: 100%|██████████| 250/250 [00:00<00:00, 444.94it/s, loss=0.0751, step=25749]
Эпоха 103: 100%|██████████| 250/250 [00:00<00:00, 460.06it/s, loss=0.0835, step=25999]
Эпоха 104: 100%|██████████| 250/250 [00:00<00:00, 397.14it/s, loss=0.082, step=26249]
Эпоха 105: 100%|██████████| 250/250 [00:00<00:00, 438.30it/s, loss=0.0891, step=26499]
100%|██████████| 1000/1000 [00:01<00:00, 504.70it/s]
Эпоха 106: 100%|██████████| 250/250 [00:00<00:00, 451.16it/s, loss=0.0916, step=26749]
Эпоха 107: 100%|██████████| 250/250 [00:00<00:00, 421.23it/s, loss=0.0841, step=26999]
Эпоха 108: 100%|██████████| 250/250 [00:00<00:00, 463.09it/s, loss=0.0767, step=27249]
Эпоха 109: 100%|██████████| 250/250 [00:00<00:00, 456.32it/s, loss=0.0623, step=27499]
Эпоха 110: 100%|██████████| 250/250 [00:00<00:00, 459.54it/s, loss=0.0964, step=27749]
100%|██████████| 1000/1000 [00:01<00:00, 500.22it/s]
Эпоха 111: 100%|██████████| 250/250 [00:00<00:00, 451.78it/s, loss=0.0784, step=27999]
Эпоха 112: 100%|██████████| 250/250 [00:00<00:00, 457.47it/s, loss=0.117, step=28249]
Эпоха 113: 100%|██████████| 250/250 [00:00<00:00, 413.68it/s, loss=0.0832, step=28499]
Эпоха 114: 100%|██████████| 250/250 [00:00<00:00, 419.91it/s, loss=0.083, step=28749]
Эпоха 115: 100%|██████████| 250/250 [00:00<00:00, 414.15it/s, loss=0.0824, step=28999]
100%|██████████| 1000/1000 [00:02<00:00, 484.85it/s]
Эпоха 116: 100%|██████████| 250/250 [00:00<00:00, 407.38it/s, loss=0.0707, step=29249]
Эпоха 117: 100%|██████████| 250/250 [00:00<00:00, 413.97it/s, loss=0.0742, step=29499]
Эпоха 118: 100%|██████████| 250/250 [00:00<00:00, 461.55it/s, loss=0.0815, step=29749]
Эпоха 119: 100%|██████████| 250/250 [00:00<00:00, 365.97it/s, loss=0.0883, step=3e+4]
Эпоха 120: 100%|██████████| 250/250 [00:00<00:00, 384.76it/s, loss=0.0958, step=30249]
100%|██████████| 1000/1000 [00:01<00:00, 511.58it/s]
Эпоха 121: 100%|██████████| 250/250 [00:00<00:00, 411.49it/s, loss=0.0867, step=30499]
Эпоха 122: 100%|██████████| 250/250 [00:00<00:00, 401.58it/s, loss=0.0794, step=30749]
Эпоха 123: 100%|██████████| 250/250 [00:00<00:00, 371.65it/s, loss=0.0924, step=30999]
Эпоха 124: 100%|██████████| 250/250 [00:00<00:00, 433.52it/s, loss=0.0852, step=31249]
Эпоха 125: 100%|██████████| 250/250 [00:00<00:00, 418.59it/s, loss=0.0731, step=31499]
100%|██████████| 1000/1000 [00:01<00:00, 536.50it/s]
Эпоха 126: 100%|██████████| 250/250 [00:00<00:00, 447.71it/s, loss=0.0888, step=31749]
Эпоха 127: 100%|██████████| 250/250 [00:00<00:00, 449.96it/s, loss=0.0752, step=31999]
Эпоха 128: 100%|██████████| 250/250 [00:00<00:00, 411.39it/s, loss=0.0826, step=32249]
Эпоха 129: 100%|██████████| 250/250 [00:00<00:00, 444.62it/s, loss=0.0973, step=32499]
Эпоха 130: 100%|██████████| 250/250 [00:00<00:00, 412.76it/s, loss=0.0668, step=32749]
100%|██████████| 1000/1000 [00:01<00:00, 530.35it/s]
Эпоха 131: 100%|██████████| 250/250 [00:00<00:00, 407.69it/s, loss=0.0928, step=32999]
Эпоха 132: 100%|██████████| 250/250 [00:00<00:00, 457.38it/s, loss=0.0892, step=33249]
Эпоха 133: 100%|██████████| 250/250 [00:00<00:00, 401.32it/s, loss=0.0902, step=33499]
Эпоха 134: 100%|██████████| 250/250 [00:00<00:00, 464.10it/s, loss=0.0861, step=33749]
Эпоха 135: 100%|██████████| 250/250 [00:00<00:00, 353.80it/s, loss=0.09, step=33999]
100%|██████████| 1000/1000 [00:01<00:00, 517.99it/s]
Эпоха 136: 100%|██████████| 250/250 [00:00<00:00, 414.15it/s, loss=0.102, step=34249]
Эпоха 137: 100%|██████████| 250/250 [00:00<00:00, 437.79it/s, loss=0.0692, step=34499]
Эпоха 138: 100%|██████████| 250/250 [00:00<00:00, 403.77it/s, loss=0.0905, step=34749]
Эпоха 139: 100%|██████████| 250/250 [00:00<00:00, 380.22it/s, loss=0.0804, step=34999]
Эпоха 140: 100%|██████████| 250/250 [00:00<00:00, 444.43it/s, loss=0.089, step=35249]
100%|██████████| 1000/1000 [00:02<00:00, 452.45it/s]
Эпоха 141: 100%|██████████| 250/250 [00:00<00:00, 443.61it/s, loss=0.0779, step=35499]
Эпоха 142: 100%|██████████| 250/250 [00:00<00:00, 407.06it/s, loss=0.0794, step=35749]
Эпоха 143: 100%|██████████| 250/250 [00:00<00:00, 373.02it/s, loss=0.0856, step=35999]
Эпоха 144: 100%|██████████| 250/250 [00:00<00:00, 402.13it/s, loss=0.0546, step=36249]
Эпоха 145: 100%|██████████| 250/250 [00:00<00:00, 323.42it/s, loss=0.0862, step=36499]
100%|██████████| 1000/1000 [00:02<00:00, 428.30it/s]
Эпоха 146: 100%|██████████| 250/250 [00:00<00:00, 354.98it/s, loss=0.079, step=36749]
Эпоха 147: 100%|██████████| 250/250 [00:00<00:00, 325.62it/s, loss=0.0919, step=36999]
Эпоха 148: 100%|██████████| 250/250 [00:00<00:00, 356.57it/s, loss=0.0771, step=37249]
Эпоха 149: 100%|██████████| 250/250 [00:00<00:00, 305.48it/s, loss=0.0925, step=37499]
Эпоха 150: 100%|██████████| 250/250 [00:00<00:00, 339.54it/s, loss=0.0839, step=37749]
100%|██████████| 1000/1000 [00:02<00:00, 406.32it/s]
Эпоха 151: 100%|██████████| 250/250 [00:00<00:00, 323.31it/s, loss=0.0748, step=37999]
Эпоха 152: 100%|██████████| 250/250 [00:00<00:00, 342.14it/s, loss=0.0808, step=38249]
Эпоха 153: 100%|██████████| 250/250 [00:00<00:00, 367.07it/s, loss=0.077, step=38499]
Эпоха 154: 100%|██████████| 250/250 [00:00<00:00, 354.85it/s, loss=0.0678, step=38749]
Эпоха 155: 100%|██████████| 250/250 [00:00<00:00, 334.65it/s, loss=0.0812, step=38999]
100%|██████████| 1000/1000 [00:02<00:00, 469.37it/s]
Эпоха 156: 100%|██████████| 250/250 [00:00<00:00, 431.41it/s, loss=0.0956, step=39249]
Эпоха 157: 100%|██████████| 250/250 [00:00<00:00, 324.39it/s, loss=0.0726, step=39499]
Эпоха 158: 100%|██████████| 250/250 [00:00<00:00, 428.28it/s, loss=0.0819, step=39749]
Эпоха 159: 100%|██████████| 250/250 [00:00<00:00, 418.23it/s, loss=0.0964, step=4e+4]
Эпоха 160: 100%|██████████| 250/250 [00:00<00:00, 427.94it/s, loss=0.0857, step=40249]
100%|██████████| 1000/1000 [00:02<00:00, 498.92it/s]
Эпоха 161: 100%|██████████| 250/250 [00:00<00:00, 405.29it/s, loss=0.0801, step=40499]
Эпоха 162: 100%|██████████| 250/250 [00:00<00:00, 387.42it/s, loss=0.088, step=40749]
Эпоха 163: 100%|██████████| 250/250 [00:00<00:00, 443.81it/s, loss=0.0699, step=40999]
Эпоха 164: 100%|██████████| 250/250 [00:00<00:00, 378.47it/s, loss=0.0854, step=41249]
Эпоха 165: 100%|██████████| 250/250 [00:00<00:00, 439.83it/s, loss=0.0841, step=41499]
100%|██████████| 1000/1000 [00:01<00:00, 531.63it/s]
Эпоха 166: 100%|██████████| 250/250 [00:00<00:00, 449.86it/s, loss=0.0739, step=41749]
Эпоха 167: 100%|██████████| 250/250 [00:00<00:00, 366.92it/s, loss=0.0732, step=41999]
Эпоха 168: 100%|██████████| 250/250 [00:00<00:00, 394.36it/s, loss=0.0731, step=42249]
Эпоха 169: 100%|██████████| 250/250 [00:00<00:00, 443.02it/s, loss=0.0694, step=42499]
Эпоха 170: 100%|██████████| 250/250 [00:00<00:00, 443.93it/s, loss=0.0918, step=42749]
100%|██████████| 1000/1000 [00:01<00:00, 525.47it/s]
Эпоха 171: 100%|██████████| 250/250 [00:00<00:00, 406.75it/s, loss=0.0996, step=42999]
Эпоха 172: 100%|██████████| 250/250 [00:00<00:00, 390.99it/s, loss=0.0863, step=43249]
Эпоха 173: 100%|██████████| 250/250 [00:00<00:00, 381.91it/s, loss=0.0783, step=43499]
Эпоха 174: 100%|██████████| 250/250 [00:00<00:00, 383.76it/s, loss=0.0957, step=43749]
Эпоха 175: 100%|██████████| 250/250 [00:00<00:00, 432.68it/s, loss=0.0847, step=43999]
100%|██████████| 1000/1000 [00:02<00:00, 409.26it/s]
Эпоха 176: 100%|██████████| 250/250 [00:00<00:00, 423.31it/s, loss=0.0727, step=44249]
Эпоха 177: 100%|██████████| 250/250 [00:00<00:00, 411.94it/s, loss=0.0899, step=44499]
Эпоха 178: 100%|██████████| 250/250 [00:00<00:00, 418.17it/s, loss=0.0798, step=44749]
Эпоха 179: 100%|██████████| 250/250 [00:00<00:00, 346.89it/s, loss=0.0937, step=44999]
Эпоха 180: 100%|██████████| 250/250 [00:00<00:00, 336.78it/s, loss=0.1, step=45249]
100%|██████████| 1000/1000 [00:01<00:00, 537.28it/s]
Эпоха 181: 100%|██████████| 250/250 [00:00<00:00, 396.20it/s, loss=0.0752, step=45499]
Эпоха 182: 100%|██████████| 250/250 [00:00<00:00, 441.72it/s, loss=0.102, step=45749]
Эпоха 183: 100%|██████████| 250/250 [00:00<00:00, 402.45it/s, loss=0.0922, step=45999]
Эпоха 184: 100%|██████████| 250/250 [00:00<00:00, 396.02it/s, loss=0.0781, step=46249]
Эпоха 185: 100%|██████████| 250/250 [00:00<00:00, 434.03it/s, loss=0.0808, step=46499]
100%|██████████| 1000/1000 [00:02<00:00, 481.68it/s]
Эпоха 186: 100%|██████████| 250/250 [00:00<00:00, 442.40it/s, loss=0.0715, step=46749]
Эпоха 187: 100%|██████████| 250/250 [00:00<00:00, 400.43it/s, loss=0.0796, step=46999]
Эпоха 188: 100%|██████████| 250/250 [00:00<00:00, 445.04it/s, loss=0.0773, step=47249]
Эпоха 189: 100%|██████████| 250/250 [00:00<00:00, 435.48it/s, loss=0.088, step=47499]
Эпоха 190: 100%|██████████| 250/250 [00:00<00:00, 427.51it/s, loss=0.0871, step=47749]
100%|██████████| 1000/1000 [00:01<00:00, 503.80it/s]
Эпоха 191: 100%|██████████| 250/250 [00:00<00:00, 378.42it/s, loss=0.0866, step=47999]
Эпоха 192: 100%|██████████| 250/250 [00:00<00:00, 403.40it/s, loss=0.0842, step=48249]
Эпоха 193: 100%|██████████| 250/250 [00:00<00:00, 445.75it/s, loss=0.0719, step=48499]
Эпоха 194: 100%|██████████| 250/250 [00:00<00:00, 400.92it/s, loss=0.0901, step=48749]
Эпоха 195: 100%|██████████| 250/250 [00:00<00:00, 402.75it/s, loss=0.0788, step=48999]
100%|██████████| 1000/1000 [00:01<00:00, 521.29it/s]
Эпоха 196: 100%|██████████| 250/250 [00:00<00:00, 391.99it/s, loss=0.0798, step=49249]
Эпоха 197: 100%|██████████| 250/250 [00:00<00:00, 382.38it/s, loss=0.0721, step=49499]
Эпоха 198: 100%|██████████| 250/250 [00:00<00:00, 429.90it/s, loss=0.0788, step=49749]
Эпоха 199: 100%|██████████| 250/250 [00:00<00:00, 400.84it/s, loss=0.0805, step=5e+4]
100%|██████████| 1000/1000 [00:01<00:00, 533.28it/s]
Сохраняем модель...
Сохраняем изображения...
Сохраняем loss в numpy-массив...
Сохраняем фреймы...
Classifier Free Guidance (будет в домашке)
✨ Classifier-Free Guidance (CFG) — трюк, который делает генерацию ближе к условию (например, к текстовому промпту) без отдельного классификатора.
🧠 На сэмплинге смешиваем два предсказания шума: безусловное и условное, \[\hat{\epsilon}=\hat{\epsilon}_{\text{uncond}} + w\big(\hat{\epsilon}_{\text{cond}}-\hat{\epsilon}_{\text{uncond}}\big).\] 🎛️ Больше \(w\) -> лучше следование промпту, но меньше разнообразия и выше риск артефактов.

❓ Вопрос: Как в диффузию добавить обусловленность на метку класса?
Ответ
Можно так же как мы кодируем таймстемп: обучить эмбэддинги и сконкатенировать с остальными входными данными.
Еще материалы про диффузионные модели
- The Annotated Diffusion Model
- Diffusion Models From Scratch
- Diffusers
- Классная лекция от AIRI по введению в диффузионки
Блиц
VAE
❓ Вопрос: Чем AutoEncoder отличается от VariationalAutoEncoder? Какая мотивация?
Ответ
VAE задаёт латент как распределение (обычно гауссово) и обучается с ELBO: reconstruction + KL-регуляризация к \(p(z)\). Из-за этого латентное пространство становится более гладким и непрерывным — интерполяция и сэмплирование дают осмысленные объекты. У обычного AE латент не регуляризован, «дыры» между кодами могут давать артефакты. Генерация в VAE: сэмплируем \(z \sim \mathcal{N}(0, I)\) и прогоняем через декодер.
❓ Вопрос: Как можно использовать AutoEncoder для задачи поиска аномалий? Какой из вариантов автоэнкодера для этого лучше всего подходит?
Ответ
Смотрим на ошибку декодера. Если декодер плохо восстанавливает данные, значит этого сэмпла не было в исходной выборке, на которой мы обучились, и это скорее всего выброс.
❓ Вопрос: Автоэнкодеры — это генеративная модель? Можно ли запустить генерацию чего-либо через автоэнкодеры? Как ей управлять?
Ответ
Да, можно. Управлять генерацией можно через интерполяцию в латентном пространстве или сэмплирование из латента (в VAE — сэмплируем \(z \sim \mathcal{N}(0, I)\) и подаём в декодер).
❓ Вопрос: Какие метрики качества можно использовать во время обучения автоэнкодеров?
Ответ
FID, IS (Inception Score). Обе метрики используют фичи/предсказания предобученной сети (Inception) и не требуют ручной разметки.
❓ Вопрос: Что такое reparametrization trick? Какую проблему он решает?
Ответ
Решает проблему распространения градиентов.
Если мы просто сэмплируем из распределения с заданными параметрами — не понятно, как распространять градиенты.

Diffusion
❓ Вопрос: Зачем в диффузии нужно большое количество шагов?
Ответ
С меньшим кол-вом шагов работает хуже или не работает. Рекомендуется ~ 1к шагов для обучения. Но вообще говоря, после обучения можно дистиллировать модель в меньшее кол-во шагов (см. Progressive Distillation, например).
❓ Вопрос: Что такое прямой процесс диффузии? Чем отличается от обратного?
Ответ
Во время прямого процесса диффузии мы зашумляем картинку. Используется только во время обучения и не последовательно по шагам, и для любого \(x_0\) мы можем вычислить \(x_t\) в идеале за константу.
Во время обратного процесса диффузии мы восстанавливаем сэмпл из шума, используя обученную модель.
❓ Вопрос: Зачем в DDPM нужен NoiseScheduler?
Ответ
NoiseScheduler задаёт расписание шума по шагам времени (beta, alpha) и хранит предвычисленные коэффициенты.
На обучении он нужен, чтобы эффективно получать \(x_t\) из \(x_0\) (add_noise), а на генерации — чтобы делать шаг обратного процесса (step) и постепенно убирать шум.
Без scheduler’а нам пришлось бы вручную и каждый раз пересчитывать формулы прямого и обратного процесса.
❓ Вопрос: Где обычно быстрее инференс — у VAE или у diffusion, и почему?
Ответ
Обычно быстрее VAE: генерация требует один проход через декодер.
У diffusion классический сэмплинг итеративный и делает много шагов денойзинга, поэтому вычислительно он заметно дороже по времени.
❓ Вопрос: Какие недостатки есть у диффузионных моделей? Как с ними можно бороться?
Ответ
Долгий сэмплинг → бороться через дистилляцию, квантизацию или прунинг.
❓ Вопрос: Чем reverse diffusion process отличается от backward?
Ответ
reverse diffusion process - процесс денойзинга
backward - процесс вычисления градиентов
❓ Вопрос (бонус): Как можно было бы сделать диффузию в дискретном пространстве?
Ответ
Бонусная идея: перейти в дискретное скрытое пространство (например, в духе VQ-подходов) и задавать прямой процесс через матрицу переходов.
Это уже расширенная тема за рамками основного материала семинара.
Если интересно углубиться: VQ-Diffusion.
Домашки
- VAE
- Diffusion (Classifier Free Guidance)